Architecture
Contexte
Regovar doit répondre aux exigeances suivantes :
* Facile à déployer au sein d'un CHU;
* Gratuit : code source déployé;
* Facile à maintenir;
* Evolutif;
Vue d'ensemble
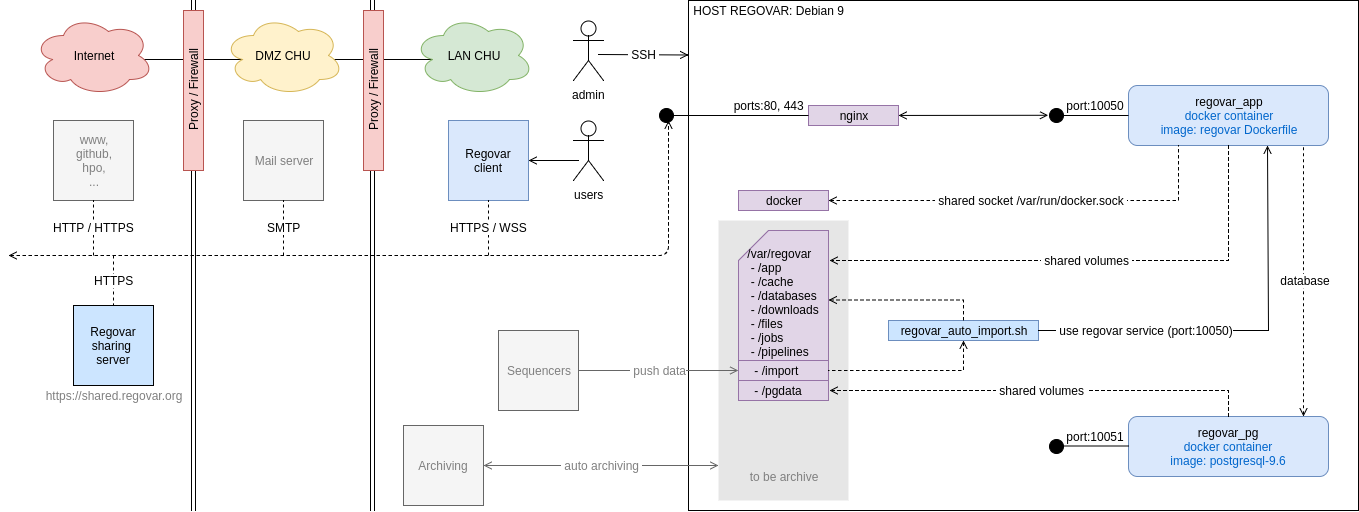
* Tout est dans le réseau local du CHU.
* Les utilisateurs accèdent au serveur régovar via le réseau local du CHU grâce au client Regovar prévu à cet effet.
* Un système de batch et de dossier partagés entre les séquenceur et le serveur Regovar peut être mis en place pour automatiser la récupération des "RUN" dans l'application Regovar, Des mails peuvent être automatiquement envoyé pour prévenir les biologistes que leurs données sont prêtes à être analysées.
Selon le même principe, un batch peut être mis en place pour que tout les weekend par exemple les données n'étant plus utilisées depuis un certains temps soient archivés et supprimé du server Regovar afin de libérer de la place. Ces mêmes batchs peuvent surveiller l'état du serveur et envoyer des alertes par mails aux administrateurs si nécessaire.
Les batchs ne font qu'utiliser les services proposés par le serveur Regovar afin d'automatiser certaines tâches. L'ensemble de ses tâches (d'ajout et de suppression de données) peuvent être faites manuellement par les utilisateurs.
Architecture Système
Config actuellement prévu pour les serveurs :
| CPU | 2x (10 coeurs / 20 threads) | INTEL XEON E5-2630V4 2.20GHZ SKT2011-3 25MB CACHE BOXED |
| RAM | 128 Go | KINGSTON DDR4 4x32 ECC REG KVR21R15D4K4/128 |
| Disques dur | 2x 4 T0 | CONSTELLATION ES.3 4TB SAS 3.5IN 7200RPM 128MB 6GB |
| Carte mère | oui | GIGABYTE MD80-TM0 CARTE MERE SERVEUR |
| Carte graphique | oui | SAPPHIRE R7 240 2G DDR3 PCI-E |
| Total | ~ 4 700€ |
Architecture applicatif
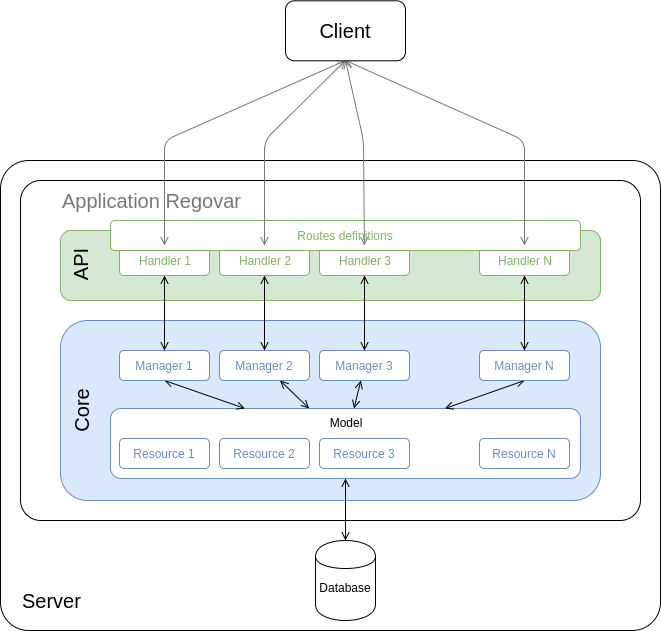
Les données sont stockées dans la base de donnée. (voir la doc sur la DB)
L'application Regovar est découpée en deux parties :
* le Core, qui est composé du Model et des Managers ;
* l'API, qui va définir un certains nombre de Handlers afin de pouvoir aider le Client à interagir avec Server. Actuellement deux API sont prévues :
* l'API Rest pour interagir à distance avec le serveur via Internet ou un réseau local;
* L'API Cli pour interagir en local directement avec le serveur via des lignes de commandes.
Le Model est la couche donnée de l'application. Ce sont des objets Python qui vont permettre d'interagir facilement avec la base de données. Et qui vont se charger notamment des opérations de sérialisation et de désérialisation entre l'application et la base de données. Elle repose sur SQLAlchemy. Pour chaque table de la base de données, des class Python dédiées vont être créées. Quand on raisonne en "API", on appelle ces données des Resources.
Les Manager sont la couche métier de l'application. Ce sont des objets Python qui vont s'occuper de manipuler les ressources du Model.